LightTrack: Finding Lightweight Neural Networks for Object Trackingvia One-Shot Architecture Search
Abstract
Snapdragon845(Adreno GPU)を使用したOceanとの速度比較の結果は以下の通り。
- Oceanの12倍高速に動作
- パラーメータ数は13分の1に削減
- Flopsは38分の1に削減

既存のモデルに比べて圧倒的に高速に動作している。

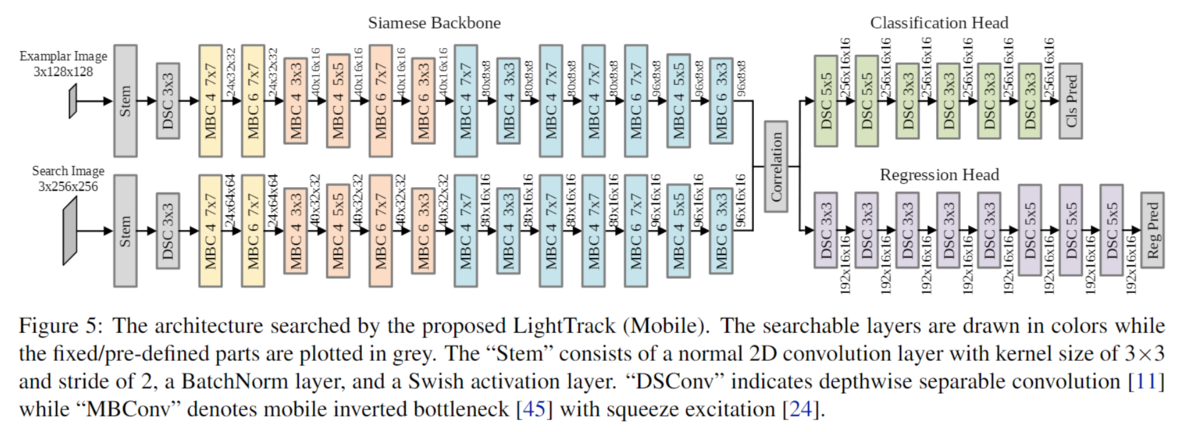
アーキテクチャ
学習時のパイプライン
学習は3ステップに分けて実行される。
1. Back BornのSupernetを学習
ImageNetで通常の画像分類タスクをcross-entropyで学習させる。
2. Tracking Supernetを学習
この段階では入力画像としてトラッキング対象の領域を切り取った画像と、その画像と対になる検索用の画像(トラッキングしたい物体が描画されている画像)を2つ受け取り、両方の特徴量を第1ステップで学習させたモデルを用いて獲得する。その後2つのCorrelationをとり、その値がHeadの部分の入力となり、HeadはClassificationとRegrression(トラッキング対象の矩形)の2つを出力する。Lossはこの2つの値で計算される。
3. 最後のステップでモデル構造の探索が実行される

モデルは3ステップで学習する。
LightTrack(mobile)
学習の結果得られたモバイルバージョンのLightTrack
機械学習プロジェクトの実験デザインについて
以下のブログを日本語に見砕いて解釈したまとめをする。
How you Should Design ML Engineering Projects
MLプロジェクトはソフトウェア開発で一般的に用いられているプロセスのイテレーションを採用することができない。
きちんと実験を計画しないと無限に続く実験を繰り返すことになってしまう。
ML Enginnering Template
Problem Statement
Goals
Softwear goals
構築したいソフトウェアシステムと機能を決める
Metrics Goals
仕事の成果を評価するときの基準は何を用いるのか、なぜその基準が用いられるのかを決める
以下、例
- Bad Example: Improve model’s performance
- OK Example: Improve AUC by X% for the model
- Good Example: Improve recall by X% for the class of false negatives without decreasing recall for any other classes by more than Y%.
Expected metrics tradeoffs, if any: For example: Increase recall without decreasing precision by more than 5%.
Experiment Design
MLプロジェクトはソフトウェアの設計とは異なり、データの収集、実験、失敗、設計の変更が起こりえます。プロジェクトを成功させるには潜在的な分岐点を適切にレイアウトすることがカギになります。またすべての実験は単純なアルゴリズムやヒューリスティックな解法と比較され、評価されなければいけません。
Data Motivation
本当に解決すべき問題なのか、解決するだけの価値、影響があるのもなのかを判断します。
Hypothesis
仮説1:Aという操作をするとBという評価基準がBaselineと比べてCだけ向上する。
Method : 実行しようとしている操作を説明する
Metric : Methodを評価するときの基準を説明する
Succes Criteria : Methodが成功したと評価されるときの基準を明らかにする
Timebox : 何日間かけて実施するのかを決める
Failure Next Step : 実験が失敗したときに何を実行するかを明らかにする(例:仮説2を検証する)
Success Next Step : 実験が成功した時に何を実行するか明らかにする(例:モデルをプロダクトに乗せる)
Softwear Design
プロジェクトのためにどのようなデータパイプライン、データベース、ソフトウェアが必要になるのか決める。
crawl
ソフトウェアの開発に時間を費やす前にその変更がどれだけの効果をもたらすのかを考える
walk
コンポーネントのより厳密な設計
run
より長期的な設計。
Considerations
Success criteria to launch?
モデルを稼働させる、もしくは入れ替えるときの評価基準について明確にする
What could go wrong?
モデルを実行させたときにうまくいかないと考えられるすべてのことを明らかにする
- どのプロダクトがモデルの影響を受ける可能性があるか
- 顧客に対してどんな影響を与えるか
- どのように監視するか
- ロールバックするにはどうすればいいか
Security & Privacy Considerations
- この変更にはセキュリティ上どんな影響があるか
- この変更がプライバシーに対してどのような影響があるか
Appendix: Experiment log
テストされた各実験の結果、途中で行われた決定、分岐点、学習結果、否定された仮説など。このような結果を後で見返したり、チームのメンバーと共有することはとても有益である。
論文紹介:Graph Convolution for Multimodal Information Extraction from Visually Rich Documents
model
グラフ畳み込みを画像に対して実施した後に、BiLSTM-CRFでエンティティを認識する。グラフ畳み込みの入力は、既存の研究がエッジの情報がないものを扱っていたのに対して、この研究ではエッジの情報をマルチレイヤーパーセプトロンを使用して予測して、その情報をもとにグラフ畳み込みを計算している。
OCR処理によって生成されたバウンディングボックスと、その中の文字情報のリスト。それぞれのノードは他のノードと全結合の形でエッジでつながっている。
グラフ畳み込みの処理は複数の層を使ってベクトルを取得する。そのベクトルとテキストのトークンの埋め込み情報をWord2Vectreを使って取得した後に、二つをconcatenateさせる。
各ノードに対して、BiLSTM-CRFを用いてテキストの埋め込み表現を獲得する。
ノード間のエッジの情報は、] という形で表現される。
GraphConvolution
Graph Convolution of Document : 出力は、各ノードのエンティティの隠れ層と、リンクに対する隠れ層の両方を出力する。
グラフ畳み込みの計算をするときには、attentionが適応されている。
リンクに対する埋め込み表現は、ノード に対してMLPを通すことで取得している。
CRF
【技術解説】CRF(Conditional Random Fields) - ミエルカAI は、自然言語処理技術を中心とした、RPA開発・サイト改善・流入改善レコメンドエンジンを開発
CRFの参考になるページ
埋め込み表現
word2vec
各矩形の文字列を埋め込みベクトルに変換する。
埋め込み表現の連結
各ノードに対して、ward2vecで取得した単語の埋め込み表現とGraphConvから得た埋め込み表現をconcatして、BiLSTM、FCL、CRFの順に連結されていく。

ノードのタグ付け
グラフ畳み込みの重みにシグモイド層を追加することで、各ノードを事前定義したクラスに分類する処理を付け加えている。いわゆるマルチタスクラーニングの処理に相当する。この時の損失の値は重み付き和で計算される。この論文内では、損失の重みの決め方に関しては Multi-Task Learning Using Uncertainty to Weigh Losses という論文のアプローチを採用している。
dataset
中国語のデータセット(フォーマットは一定)のものと、たぶんICDARのOCRからの情報抽出で使用されているデータセット(英語、フォーマットは可変)を使用している。
ラグランジュの未定乗数法をpythonで実装する
最近「これならわかる最適化数学基礎原理から計算手法まで」を購入し、読み進めています。今回はラグランジュの未定乗数法の例題をpythonで実装してみようと思います。
ラグランジュ未定乗数法を簡単にまとめる以下の通りです。
制約条件が1つの場合
- 制約条件が $x+y+z=1$ のもとでの関数 $f(x,y,z)=xy^2z^3$ の極致を求めよ p.67
上の定理を用いると、制約条件を として、
と置くことができます。
ここで一度、関数fと、関数g、関数Fを実装しておきます。
pythonのsympyライブラリを使用して微分を計算します。
from sympy import diff, symbols, solve # 変数を定義 x, y, z, l = symbols("x y z l") # 関数fを定義 f = x * y**2 * z**3 # 制約条件gを定義 g = x + y + z - 1
各変数に関して偏微分してその結果を0と置くと
となります。
この偏微分の部分は、pythonのコードで書くと、
# 定理式に代入 theor = f - l * g # 各変数で偏微分する diffx = diff(theor, x) diffy = diff(theor, y) diffz = diff(theor, z) diffl = diff(theor, l) res = solve([diffx, diffy, diffz, diffl])
この連立方程式を解くことで極値をとるときのx, y, zの値がわかります。
上の連立方程式を解くと、
となります。この時の関数fの値は、 となる。
pythonコード全体は以下の通りです。
from sympy import diff, symbols, solve # 変数を定義 x, y, z, l = symbols("x y z l") # 関数fを定義 f = x * y**2 * z**3 # 制約条件gを定義 g = x + y + z - 1 # 定理式に代入 theor = f - l * g # 各変数で偏微分する diffx = diff(theor, x) diffy = diff(theor, y) diffz = diff(theor, z) diffl = diff(theor, l) # 連立方程式を解く res = solve([diffx, diffy, diffz, diffl])
seabornでダークモードの状態でグラフを描写する
グラフを描画する前に
plt.style.use("dark_background")
を書くことで解決できました。
Ridge回帰
Kaggleのテーブルデータコンペなどで役に立ちそうなモデルの一つとして、リッジ回帰についてまとめていこうと思います。リッジ回帰の特徴は、独立変数の係数の大きさに制約を設けることです。そうすることで正則化の効果を得ることができます。
Ridge回帰は何をやっているのか?
回帰分析をする際、OLS推定ができるときの条件が存在します。
Ⅰ.回帰モデルは線形で、正しく記述されており、加法的な誤差項をもつ。
Ⅱ.誤差項の母平均は0である。
Ⅲ.説明変数は誤差項と無相関である。
Ⅳ.誤差項の観察値は互いに無相関である。(系列相関なし)
Ⅴ.誤差項の分散は均一である。(不均一分散なし)
Ⅵ.すべての説明変数は、他の一連の説明変数の完全な線形関数ではない。(完全な多重共線性なし)
Ⅶ.誤差項は正規分布に従う。(この仮定は付属的なものだが、通常は用いられる)計量経済学の使い方上[基礎編]p102
上記の条件を満たしていないときにOLSを用いてしまうと、信頼度の低い結果しか得られなくなってしまうのです。その場合、OLS以外の推定方法が用いられます。リッジ回帰は上の条件の中の多重共線性の条件が満たされないときに効果を発揮します。
仮に、多重共線性の問題がクリアされていない場合にOLSを用いたとします。そうすると、推定された係数の分散が大きくなってしまいます。分散が大きくなると係数の取りうる値の範囲が広くなります。これが、「信頼度の低い結果しか得られなくなる」という意味です。
この問題を克服するために、Ridge回帰では各独立変数の係数の二乗の和が大きくならないように制約を課します。直感的には以下の式がわかりやすいです。
式の第一項目は通常のOLSで用いられているものです。第二項目は、係数の推定値の二乗和にパラメータλの積です。λの値が大きくなるほど、モデルの係数推定値は大きい値をとりにくくなります。また、係数の二乗和の値の最大値を明示的に提示する場合には、以下のような書き方もできます。
この場合係数の推定値の二乗和はtの値より大きくなることはありません。
どんな時に役に立つのか?
では係数の二乗和を小さくすることに何のメリットがあるのでしょうか?
その答えとして変数選択が考えられると思います。いま、30個の独立変数を用いて、一つの従属変数を予測するという課題が与えられたとします。この様な場合、背景にある理論や原理に基づいて変数を選択することが最初のアプローチですが、それだけでは完全に決めきれないことが一般的です。そのようなときに変数選択の基準となる指標となるものが欲しくなります。その役割を果たしてくれるのがRidge回帰です。Ridge回帰の制約の強さを決めるλの値をいろいろ変えながら本当に「重要な変数」を選ぶことができます。そして多くの場合、Ridge回帰で推定された係数を用いたモデルは、OLSを用いて推定したモデルよりも「予測において」精度が高くなります。
Boston House Price で検証
scikit learnで提供されているデータを用いて実際にRidg回帰適応してみます。
以下にコードを載せます。
import numpy as np import pandas as pd import matplotlib.pyplot as plt import matplotlib.ticker as ticker from sklearn.datasets import load_boston # scaling and dataset split from sklearn import preprocessing from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression, Ridge from sklearn.metrics import r2_score, mean_squared_error
house_price = load_boston() df = pd.DataFrame(house_price.data, columns=house_price.feature_names) df["PRICE"] = house_price.target house_price.data = preprocessing.scale(house_price.data) X_train, X_test, y_train, y_test = train_test_split( house_price.data, house_price.target, test_size=0.3, random_state=10)
ridge_reg = Ridge(alpha=0) ridge_reg.fit(X_train, y_train) ridge_df = pd.DataFrame({"variable":house_price.feature_names, "estimated":ridge_reg.coef_}) ridge_train_pred = [] ridge_test_pred = []
for alpha in range(0, 200, 1): ridge_reg = Ridge(alpha=alpha) ridge_reg.fit(X_train, y_train) var_name ="estimate" + str(alpha) ridge_df[var_name] = ridge_reg.coef_ ridge_train_pred.append(ridge_reg.predict(X_train)) ridge_test_pred.append(ridge_reg.predict(X_test)) ridge_df = ridge_df.set_index("variable").T ridge_df.index = range(0, 201)
fig, ax = plt.subplots(figsize=(10, 5)) ax.plot(ridge_df.RM, "r", ridge_df.ZN, "g", ridge_df.RAD, "b", ridge_df.CRIM, "c", ridge_df.TAX, "y") ax.axhline(y=0, color="black", linestyle="--") ax.set_xlabel("Lambda") ax.set_ylabel("Beta Estimation") ax.set_title("Ridge Regression Trace", fontsize=16) ax.legend(labels=["Room", "Residential Zone", "Highway Access",'Crime Rate','Tax']) ax.grid = True

いくつかの変数を抽出して、λの値(制約の強さ)と係数の大きさの関係を調べてみます。
最も変化の大きい変数は「Highway access」です。制約が弱いときには一番係数の絶対値が大きかったのですが、制約が強くなるにつれて小さくなっていき、最終的には最も0に近くなります。対照的に変数Room(居住施設の平均部屋数)は制約が強くなっても係数が比較的大きいままです。
ridge_mse_test = [mean_squared_error(y_test, p) for p in ridge_test_pred] # ols_mse = mean_squared_error(y_test, ols_pred) # plot mse plt.plot(ridge_mse_test[:50], 'ro') # plt.axhline(y=ols_mse, color='g', linestyle='--') plt.title("Ridge Test Set MSE", fontsize=16) plt.xlabel("Model Simplicity$\longrightarrow$") plt.ylabel("MSE")

最後にλの値とテストセットにおける予測精度の関係を示します。λ=0のとき、つまりOLS推定の時よりも少し制約をかけた時の方が精度がよいことがわかります。一番予測精度がよくなっているのは、λの値が7、8くらいの時です。
Global Average Pooling とは
概要

2番目の畳み込み層が64チャンネル × (7×7)の出力していて、最後のGAP層はその出力を受け取っている。GAPは、前の畳み込み層の出力(7×7)の平均をとることによって、1次元、64チャンネルに圧縮している。最終的には10クラスの分類結果を出力している。